R의 제작 환경을 knime내에서 쓰는 방법입니다.Knime에 없는 모듈이 있고 필요한 부분만 가끔 R에서 읽기 방법입니다.입출력 부분만 제어하면 간단한 R분석을 단일 모듈화하고 사용할 수 있습니다.Knime 같은 모듈화, 병렬화 분석에는 메리트가 될 수 있습니다.직렬 연결에 의존하는 스크립트 기반의 분석에 익숙한 분은 논외 세계의 장점이므로 관심 있는 것에만 의미가 있습니다.본 샘플에서는 Knime기본 기능에 포함되지 않은 한글 자연 언어 형태소를 간단히 구현합니다.Knime이 R을 쓰기 위해서는 기본적으로 install.packages(‘Rserve’)을 우선 설치할 필요가 있습니다.Rserve및 필요한 패키지(예를 들어 konlp등)은 기본적으로 R에서 먼저 설치할 필요가 있습니다.R의 사용법까지 설명하기 어렵고, 이하의 링크에 바뀝니다.https://docs.knime.com/2019-12/r_installation_guide/index.html#r_packages_installation
KNIME인터렉티브 R 통계 정보 통합 설치 가이드 개요 이 가이드에서는 KNIME Analytics Platform에서 사용하는 KNIME Interactive R Statistics Integration 설치 방법에 대해 설명합니다. KNIME Interactive R Statistics Integration에서는 외부 R 설치와 대화를 통해 R 스크립트 쓰기 및 실행이 가능합니다. 이 통합은 docs.knime.com 로 구성되어 있습니다.

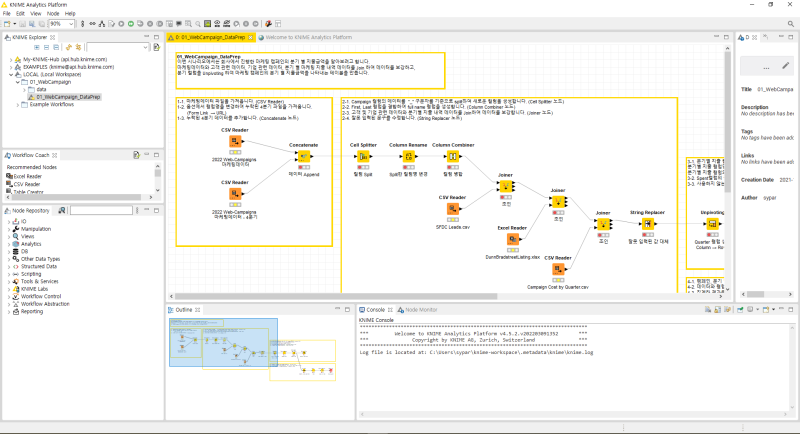
Knime 내 R을 사용하기 위한 환경을 설정합니다. File > preferences > knime > R 에서 아래와 같이 찾습니다.

Knime 내 R을 사용하기 위한 환경을 설정합니다. File > preferences > knime > R 에서 아래와 같이 찾습니다.

Path to R Home에서 컴퓨터에 설치된 R(사용 패키지가 설치되어 있음) 폴더를 찾습니다. 그러면 사용은 끝납니다. Rserve 패키지가 본R버전에 설치되어 있지 않으면 기본적으로 사용할 수 없습니다. 소개 샘플은 R에서 한글의 자연어 명사를 추출하는 전처리 샘플입니다. Knime에서 사용하는 R버전에 Rserve 뿐만 아니라 konlp까지 먼저 설치해주세요. 또한 한글 전처리기를 사용하기 위해서는 앞서 python 사례처럼 자바시드가 설치되어 있어야 합니다.

이런 한글 텍스트 묶음을 넣어서
한글 명사를 정제하는 모듈을 하나 만들고 한글 명사를 문서에서 추출합니다.
R스크립트에서 꼭 필요한 세팅만 소개합니다, 굳이 R형태소 분석 코딩까지 설명하지 않습니다.Java se가 설치된 패스는 설정하세요.그리고 기본적으로 konlp패키지는 설치되어 있어야 합니다.다음은 knime에서 입력된 문서를 한글의 전처리하는 모듈입니다.그 후, 머신 러닝, 네트워크 분석, 기타의 가시화를 실시할 수 있습니다.명사 형태소 추출하지 않고 lucene검색 엔진에서 처리하는 것도 있습니다.활용 법은 개인의 선택이라.R로 짠 통상의 코드는 1개 사용 동안에 다른 일이 없는데 Knime에서 좀 편법이 편하게 사용할 수 있습니다.모듈화된 R자연 언어 처리 모듈을 병렬로 접속할 수 있습니다.문서 하나에 걸린 텍스트의 수가 큰 편인데 관련된 문서 수가 많다고 중간에 자주 나옵니다.언제 늘까 모르겠습니다만, 이것을 잘게 분할하고 처리하겠습니다.또 한글 형태소 분석 모듈을 복수 동시에 돌릴 수 있습니다.생각보다 1개의 모듈로 처리하는 속도가 늦지만, 컴퓨팅 자원은 남는 것이 많습니다.컴퓨터의 사정에 의해서 달랐지만 나의 경우는 4개까지 같이 돌리면 속도가 좋았습니다.어차피 시간 노동 때문에 처리 시간을 줄이는데 도움이 됩니다.
R스크립트에서 꼭 필요한 세팅만 소개합니다, 굳이 R형태소 분석 코딩까지 설명하지 않겠습니다. Java se가 설치되어 있는 경로는 설정해 주세요. 그리고 기본적으로 konlp 패키지는 설치되어 있어야 합니다. 아래는 knime으로 입력된 문서를 한글 전처리하는 모듈입니다. 그런 다음 머신러닝, 네트워크 분석 및 기타 가시화를 수행할 수 있습니다. 명사 형태소 추출하지 않고 lucene 검색 엔진으로 처리하기도 합니다. 활용법은 개인의 선택이기 때문에. R로 짠 일반 코드는 하나 돌리는 동안 다른 일을 할 수 없는데, Knime에서 조금 편법을 편하게 사용할 수 있습니다. 모듈화된 R 자연어 처리 모듈을 병렬로 연결할 수 있습니다. 문서 하나당 걸리는 텍스트 수가 큰 편인데 걸리는 문서 수가 많으면 중간에 잘 늘어나요. 언제 늘어날지 모르겠는데 이거 잘게 쪼개서 처리할게요. 또한 한글 형태소 분석 모듈을 여러 개 동시에 돌릴 수 있습니다. 생각보다 한 모듈로 처리하는 속도가 느리지만 컴퓨팅 리소스는 남는 경우가 많습니다. 컴퓨터 사정에 따라 다르지만 저 같은 경우는 4개까지 같이 돌리면 속도가 좋았습니다. 어차피 시간 노동이기 때문에 처리 시간을 줄이는 데 도움이 됩니다.